





目次
はじめに
LLM(大規模言語モデル)を業務で活用する際、避けて通れない課題の一つが「ドキュメントをどう入力するか」です。
特に、ExcelやWord、PowerPointで作られた資料には、
・フロー図
・構成図
・関係図
といった人間が直感的に理解しやすい「視覚的に意味を持つ情報」が多く含まれています。
しかし、これらのテキスト部分のみ抽出しても、図としての意味や構造はほとんど失われてしまいます。
LLMには入力できるトークン数(コンテキスト長)に制限があり、VLMによる画像解析は有効ですが、トークン数を多く消費するため、不要な情報を削減しつつテキスト構造として維持することが重要になります。
また、トークン数が多いほど処理負荷が高くなるため、入力データを適切に整理することは、処理速度やコストの観点からも重要です。更にトークン数を削減することは特にローカルAIを運用する上で重要な要素です。
本記事では、
- 視覚情報を構造データとして扱うアプローチ
- 座標付きマークダウン化による検証結果
について紹介します。
現在は開発・検証段階ですが、同様の課題をお持ちの方との議論・協業も視野に入れています。
きっかけ:社内ドキュメントを見直して気づいたこと
社内ドキュメントをAI活用に連携する検討を進める中で、過去の資料を改めて見直したところ、ある特徴に気づきました。
ExcelやWord、PowerPointといった資料の多くが、テキストだけでなく、図やフローによって構造を表現していました。
これらの情報をAIに取り込むために、既存の抽出ツールやマークダウン変換ツールもいくつか試しましたが、
図解の構造がうまく伝わらないという課題に直面しました。
テキストは取得できても、図形の配置、フローの方向、グルーピングといった視覚的な意味が失われてしまい、AIに意図を正確に伝えるには不十分でした。
この経験から、「図解をそのままではなく、構造として扱う必要がある」と考えるようになりました。
既存の手段で難しいのであれば、自分たちで実現するしかない。
そうした背景から、本アプローチの検討と開発に至っています。
視覚情報をAIにどう伝えるかという課題
社内ドキュメントには、図解によって表現された情報が多く存在します。
例えば、
・図形の位置関係
・矢印による処理の流れ
・グルーピングによる意味の区分
といった要素です。
これらは人間にとっては直感的に理解できますが、単純なテキスト抽出では、構造が崩壊した状態のデータになってしまいます。
その結果、
・フローが再現できない
・要素の関係性が曖昧になる
という問題が発生します。
既存ツールではなぜ不十分だったのか
この課題に対して、既存のマークダウン変換ツールや抽出ツールを試しましたが、
・テキストは取得できる
・しかし構造は保持されない
という状態に留まりました。
特に問題となるのは、図形の「位置」や「配置関係」といった空間情報が欠落することです。
AIはテキストの理解には優れていますが、構造の手がかりがなければ、関係性やフローを推定することが難しいという課題があります。
解決アプローチ:座標付きマークダウン化
そこで着目したのが、視覚情報を “構造データ” として保持するアプローチ です。
単純にテキスト化するのではなく、
・テキスト
・図形の種類
・位置・サイズの座標情報
を組み合わせて扱うことで、AIが構造を推定・再構成できる状態を作ります。
この要件を満たすために、
- 図形情報を含めて解析し
- 座標情報付きで抽出し
- マークダウンとして構造化する
処理系の開発を進めています。
ポイントはシンプルで「どこにあるか(座標)」をAIに渡すことです。
これによりAIは、
・上下関係
・左右の並び
・グルーピング
といった構造情報をもとに、ドキュメント全体の意味を推定できるようになります。
さらに本アプローチでは、単に視覚情報をテキスト化することを目的とするのではなく、AIが推論に活用できる形で情報を再構成することを意図しています。
また、副次的な効果として、不要な装飾情報を削減することでトークン効率の改善も期待できます。
技術選定(C#.NET を採用した理由)
AI処理の分野ではPythonが主流ですが、本処理系の開発には C#.NET を採用しています。
理由は大きく3つあります。
■ 既存業務システムとの親和性
多くの企業システムは、.NETベースで構築されています。
そのため、
・既存システムとの連携
・社内ツールとしての組み込み
を考えた場合、C#.NET の方が現実的です。
■ Officeドキュメントとの相性
今回対象としている
・PowerPoint
・Excel
・Word
といったファイルは、Windows環境・.NETとの相性が良く、図形やレイアウト情報の取得においても扱いやすいという利点があります。
■ 運用・保守の現実性
Python環境を新たに構築・維持するよりも、
・既存の技術スタックで完結できる
・依存ライブラリが少なく軽量であり高速処理が可能
・社内での運用負荷を抑えられる
といった点を重視しました。
実証:視覚情報からのフロー再構築
本アプローチの有効性を検証するため、PowerPoint資料を対象に実証を行いました。
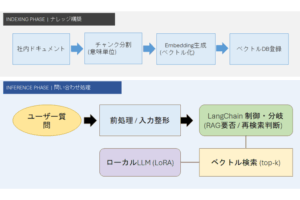
事例1:全体アーキテクチャの解析
⇒⇒⇒
座標付きマークダウン化
AIによる解析・再構築
⇒⇒⇒
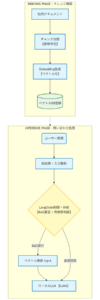
フロー図を座標付きマークダウンに変換し、ローカルAIに入力した結果、
・フェーズの分離
・グループ認識
・フローの方向性を推定
が可能であることを確認しました。
フロー図部分のマークダウン化した情報(抜粋)はこちらをクリックすると、確認できます。
### 2-1. 全体アーキテクチャ(スライド6ベース)
インデックス作成フェーズと推論フェーズの全体像を示します。
```mermaid
flowchart TD
%% スタイル定義
classDef phase fill:#f9f9f9,stroke:#333,stroke-width:2px;
classDef process fill:#e1f5fe,stroke:#0277bd,stroke-width:2px;
classDef decision fill:#fff9c4,stroke:#fbc02d,stroke-width:2px;
classDef db fill:#e8f5e9,stroke:#2e7d32,stroke-width:2px;
subgraph IndexingPhase [INDEXING PHASE -- ナレッジ構築]
direction TB
Doc[社内ドキュメント]:::process --> Chunk[チャンク分割<br/>【意味単位】]:::process
Chunk --> Embed[Embedding生成【ベクトル化】 ]:::process
Embed --> VecDB[(ベクトルDB登録)]:::db
end
subgraph InferencePhase [INFERENCE PHASE -- 問い合わせ処理]
direction TB
UserQ(ユーザー質問):::process --> PreProc[前処理 / 入力整形]:::process
PreProc --> LangChain{LangChain制御・分岐<br/>【RAG要否 / 再検索判断】}:::decision
%% RAGが必要な場合のフロー
LangChain -- RAG実行 --> VecSearch[ベクトル検索 top-k]:::process
VecSearch --> LLM[ローカルLLM 【LoRA】]:::process
%% RAG不要な場合(直接回答)
LangChain -- 直接回答 --> LLM
end
%% フェーズ間の接続(概念的)
IndexingPhase -.-> InferencePhase
```Tips: マークダウンの編集に慣れていない方へ
AIが生成したテキストを自分好みに整形したい場合は、マークダウンの基本ルールを知っておくとスムーズです。
こちらの記事で詳しく解説されています。
マークダウンとは?基本の書き方とメリット(外部サイト)
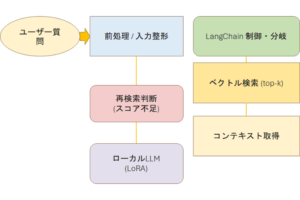
事例2:曖昧な図のロジック補完
⇒⇒⇒
座標付きマークダウン化
AIによる解析・再構築
⇒⇒⇒
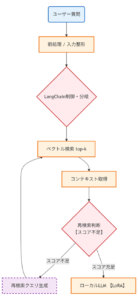
この事例では、PowerPointの図解は「明確な矢印が存在しない」「関係性が暗黙的」という人間特有のふんわりした状態ですが、
・フローのつながりを推定
・不足ステップの補完
・フィードバックループを構築
が行われ、論理的に一貫した構造へ再構築されました。
図解部分のマークダウン化した情報(抜粋)はこちらをクリックすると、確認できます。
### 2-2. RAG詳細フロー:再検索ループ強調(スライド7ベース)
LangChainによる制御と、スコア閾値に基づいた再検索のループ構造を詳細に記述します。
```mermaid
flowchart TD
%% スタイル定義
classDef startend fill:#e3f2fd,stroke:#1565c0,stroke-width:2px;
classDef process fill:#fff3e0,stroke:#ef6c00,stroke-width:2px;
classDef decision fill:#ffebee,stroke:#c62828,stroke-width:2px;
classDef loop fill:#f3e5f5,stroke:#7b1fa2,stroke-width:2px,stroke-dasharray: 5 5;
Start(ユーザー質問):::startend --> PreProc[前処理 / 入力整形]:::process
PreProc --> Control{LangChain制御・分岐}:::decision
%% 検索実行
Control --> Search[ベクトル検索 top-k]:::process
Search --> Context[コンテキスト取得]:::process
%% スコア評価と再検索判断
Context --> ScoreCheck{再検索判断<br/>【スコア不足】}:::decision
%% ループ処理
ScoreCheck -- スコア不足 --> ReQuery[再検索クエリ生成]:::loop
ReQuery --> Search
%% 正常終了フロー
ScoreCheck -- スコア充足 --> LLM[ローカルLLM 【LoRA】]:::process
```これらの事例から、座標による構造理解とAIの文脈理解が組み合わさることで、
従来は難しかった図解のAI活用が現実的に可能になることが確認できました。
今後の展開
本アプローチはまだ開発段階ですが、いくつかの拡張も検討しています。
例えば、文書に含まれる画像についても、
・抽出画像のOCRによるテキスト化 (画像としての抽出機能・マーカー挿入機能あり)
・マークダウンへの統合
といった処理を組み合わせることで、図解に含まれる情報の補完や、より一貫した構造化が可能になると考えています。
図解を含むドキュメントのAI活用は、まだ十分に整理されていない領域です。
本取り組みは、その中で視覚情報を構造データとして扱うための一つのアプローチと位置づけています。
同様の課題をお持ちの方がいれば、ぜひ情報交換できればと思います。
まとめ
人間向けに設計された図解資料であっても、構造を保った形でデータ化することで、AIが扱える情報へと変換できます。
本アプローチのポイントは、「構造を保ったままトークン効率を改善する」ことにあります。
図解を含むドキュメントのAI活用や、ナレッジ化・RAGへの応用など、さまざまな可能性があると考えています。
おわりに(協業のご案内)
現在、ローカルAIの利活用に関わる様々な環境の開発・検証段階にあります。
・同様の課題をお持ちの方
・ドキュメント処理 × AIに関心のある方
・自社システムへの組み込みを検討されている方
・ローカルAIの運用を検討されている方
がいらっしゃいましたら、ぜひお気軽にお声がけください。
※お急ぎの場合はお電話でも承っております。
コメント